
Appearance

大家好,我是 Ai 学习的老章
DeepSeek-R1-0528 很强
但,即便是量化版本地部署起来也成本巨高
我还是关心 DeepSeek 同步开源的一个小型——DeepSeek-R1-0528-Qwen3-8B
看看其能否低成本地替换某些工作流中的 Qwen3:32B
本文,我用2张 4090 显卡部署它,然后和 4 卡运行起来的 Qwen3:32B 做个对比
DeepSeek-R1-0528-Qwen3-8B
这个模型是从 DeepSeek-R1-0528 的思维链蒸馏出来用于后训练 Qwen3 8B Base 而得。
通过蒸馏技术,在 AIME 2024 上达到 86.0,超越 Qwen3-8B (+10%),媲美更大模型!
DeepSeek-R1-0528-Qwen3-8B 在 2024 年美国数学邀请赛(AIME)上的开源模型中取得了最先进(SOTA)的性能,比 Qwen3 8B 提高了 10.0%,性能与 Qwen3-235B-thinking 相当。
| AIME 24 | AIME 25 | HMMT Feb 25 | GPQA Diamond | LiveCodeBench (2408-2505) | |
|---|---|---|---|---|---|
| Qwen3-235B-A22B | 85.7 | 81.5 | 62.5 | 71.1 | 66.5 |
| Qwen3-32B | 81.4 | 72.9 | - | 68.4 | - |
| Qwen3-8B | 76.0 | 67.3 | - | 62.0 | - |
| Gemini-2.5-Flash-Thinking-0520 | 82.3 | 72.0 | 64.2 | 82.8 | 62.3 |
| o3-mini (medium) | 79.6 | 76.7 | 53.3 | 76.8 | 65.9 |
| DeepSeek-R1-0528-Qwen3-8B | 86.0 | 76.3 | 61.5 | 61.1 | 60.5 |
下载模型
模型文件:https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B/files

在下载前,先通过如下命令安装 ModelScope
pip install modelscope
命令行下载完整模型库
modelscope download --model deepseek-ai/DeepSeek-R1-0528-Qwen3-8B --local_dir .
模型大小约 16GB
部署
看介绍,它的模型架构与 Qwen3-8B 完全相同,只是与 DeepSeek-R1-0528 共享相同的分词器配置,所以,部署的话与 Qwen3-8B 没啥区别。
用 vllm 拉起大模型
bash
pip install --upgrade vllm
CUDA——VIDIBLE_DEVICES=4 vllm serve . --served-model-name R1-0528-Qwen3-8B 3002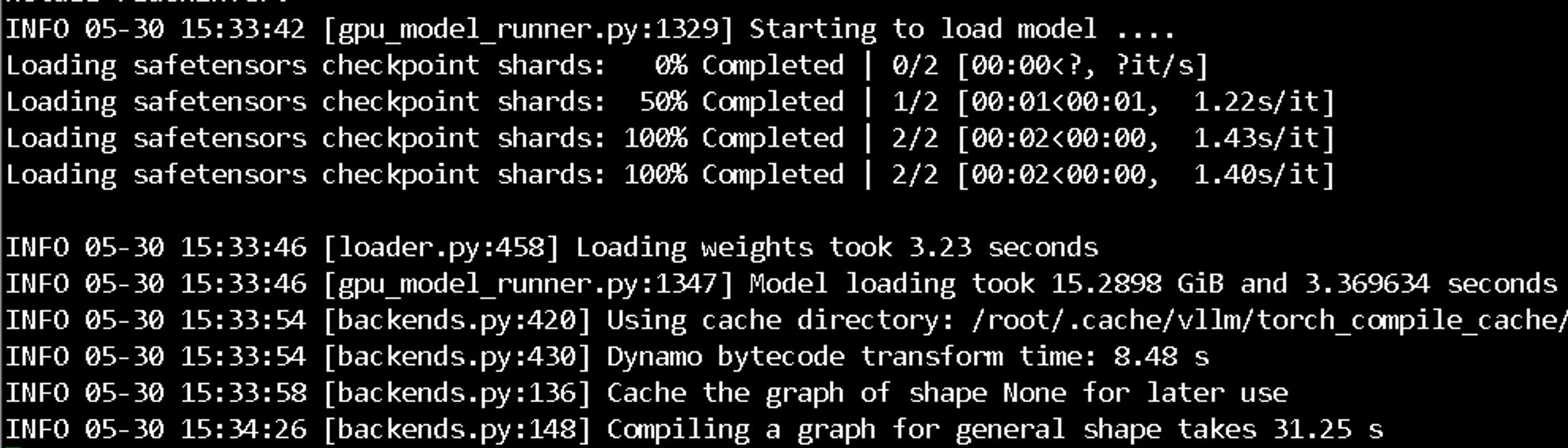
默认参数的 max_model_len 是 131072,需要 18GB 的 KVcache 空间
4090 只有 24G,不够用

要想拉起来,要么降低 max_model_len,要么两张 4090
我选择后者
bash
pip install --upgrade vllm
CUDA_VIDIBLE_DEVICES=4,5 vllm serve . --served-model-name R1-0528-Qwen3-8B 3002 --tensor-parallel-size 2
openwebui 聊天助手
测试窗口,我是用 openwebui
OpenWebUI 旨在为 AI 和 LLMs 构建最佳用户界面,为那些互联网访问受限的人提供利用 AI 技术的机会。OpenWebUI 通过 Web 界面本地运行 LLMs,使 AI 和 LLMs 更安全、更私密。
安装 openwebui 是我见过所有 chatbot 中最简单的了
shell
# 安装
pip install open-webui
# 启动
open-webui serve浏览器打开 http://locahost:8080
如果是服务器部署,把 localhost 改为服务器 ip
正常注册登陆
右上角点击头像,点击管理员面板
点击设置 - 外部链接,照着抄一下,api key 随便填写
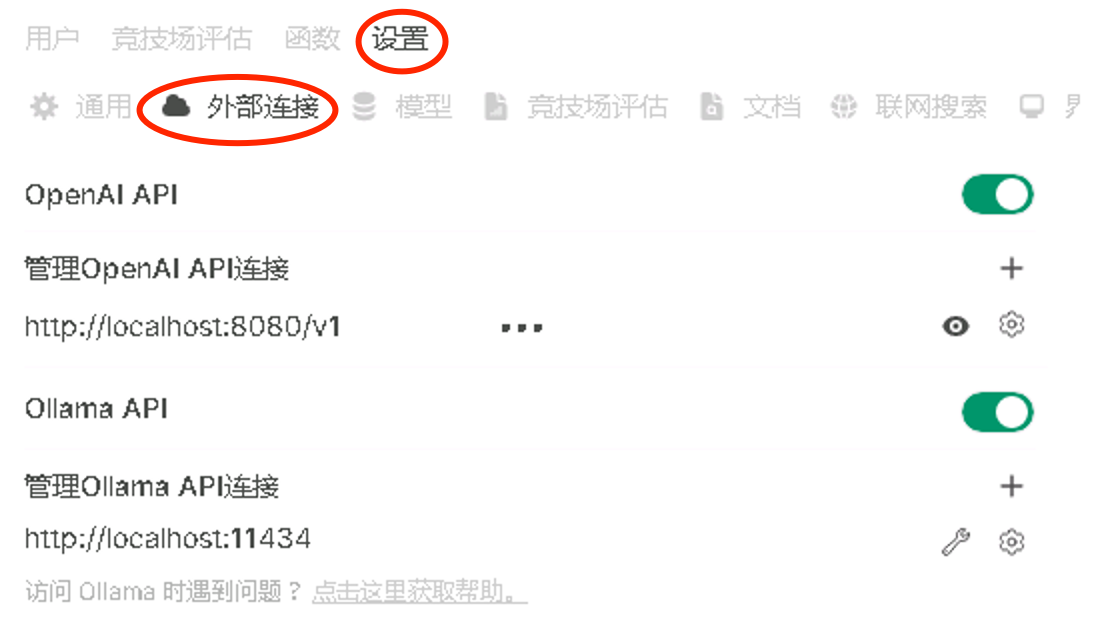
然后回到前端,左上角添加模型那里就可以找到 R1-0528-Qwen3-8B 了
teminal 页面会实时输出模型推理时的性能
推理速度可以做到 90Tokens/s
Qwen3:32B 之前我介绍过 [[2025-04-29-阿里 Qwen3 本地部署,4张 4090 跑起]]。40Tokens/s的样子

具体测试我需要后续再写了,有点忙,先看几个简单问题的对比:

我觉得DeepSeek-R1-0528-Qwen3-8B 的自我介绍非常棒🎉
作为对比,大家可以看看我之前这篇文章:DeepSeek-V3、DeepSeek-R1、Kimi、Qwen3、ChatGPT、Gemini的自我介绍对比
问题2:用html写一个黑客帝国数字雨

DeepSeek-R1-0528-Qwen3-8B 努力地尝试设计更多功能,比如滴答声效、闪烁效果、键盘控制和交互功能,但是,运行有bug❌
Qwen3:32B,老是本分,简单生成了数字/字母雨效果,运行正常✅
问题3:总结DeepSeek-R1-0528这篇文论

感觉上DeepSeek-R1-0528-Qwen3-8B 更好一些,思考的很快(5s vs 18s),结尾还会友情提示是否需要追问某些细节

后续我再认真测试解决bug、知识问答
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
搭建完美的写作环境:工具篇(12 章)图解机器学习 - 中文版(72 张 PNG)ChatGPT、大模型系列研究报告(50 个 PDF)108 页 PDF 小册子:搭建机器学习开发环境及 Python 基础 116 页 PDF 小册子:机器学习中的概率论、统计学、线性代数 史上最全!371 张速查表,涵盖 AI、ChatGPT、Python、R、深度学习、机器学习等
