
Appearance
大家好,我是 Ai 学习的老章
现在的大模型应用搭建越来越深入,但是安全层面大家普遍不够重视,各种提示词越狱,注入,投毒等手段,无论是基模还是最终应用,都极有可能输出不安全内容(比如暴力、非法行为、个人可识别信息、不道德行为、敏感话题、版权侵犯等)。
[[2025-09-24-阿里太疯狂了,但,最强大模型不开源了]] 一文中,提到 Qwen3Guard 安全审核模型
我部署了,将其放在工作流第一步的提示词安全性审核以及最终回复的安全性审核
双重保障,能够一定程度降低安全风险。
它的使用极其简单,就是给提示词和最终回复打标签和分类

本文极简介绍本地部署与用法
Qwen3Guard
阿里开源的 Qwen3 安全审核模型Qwen3Guard,一共 2 个,分两类:
- Qwen3Guard-Gen,将安全性分类视为指令跟随任务的生成模型;
- Qwen3Guard-Stream,在增量文本生成期间实时进行安全监控的标记级分类头。
这两类模型又分别有三种大小的模型(0.6B、4B 和 8B)
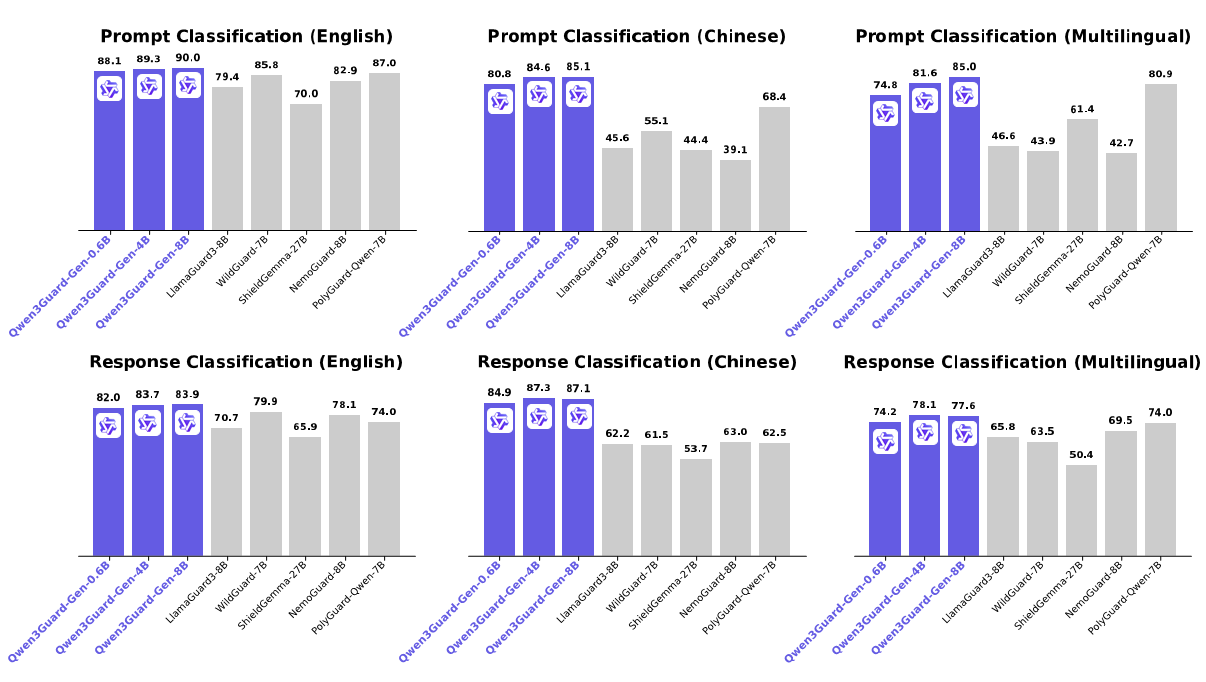
应用场景:
- Qwen3Guard-Gen(生成式版) 支持对完整用户输入与模型输出进行安全分类,适用于离线数据集的安全标注、过滤,亦可作为强化学习中基于安全性的奖励信号源,是构建高质量训练数据的理想工具。
- Qwen3Guard-Stream(流式检测版) 突破了传统的护栏模型架构,首次实现模型生成过程中的实时、流式安全检测,显著提升在线服务的安全响应效率与部署灵活性。
Qwen3Guard-Gen,它具有以下主要优势:
- 三级严重性分类:通过将输出分类为安全、有争议(其危害性可能依赖于上下文或在不同应用场景中存在分歧的内容)和不安全(通常被认为在大多数情况下有害的内容)三个严重性级别,支持对不同部署场景的适应。
- 多语言支持:Qwen3Guard-Gen 支持 119 种语言和方言,确保在全球和跨语言应用中的强大性能。
- 卓越的性能:Qwen3Guard-Gen 在各种安全基准测试中表现出色,在英语、中文和多语言任务的提示和响应分类方面均表现优异。
本地部署
第一步,下载模型
我选择了 4B 版本
bash
pip install modelscope
modelscope download --model Qwen/Qwen3Guard-Gen-4B --local_dir /Qwen3Guard-Gen-4B
第二步,vLLM 启动
vLLM 版本 0.10.2
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3Guard-Gen-4B --port 8000 --max-model-len 32768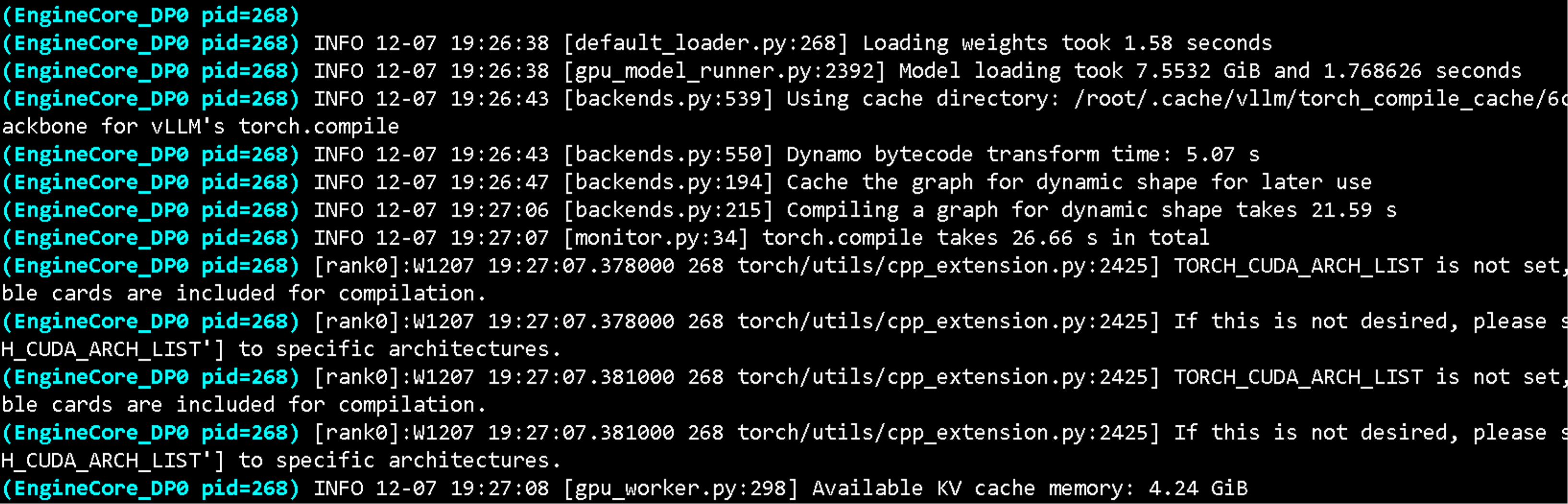
实际上,我把 max-modle-len 设置为了 10240,给它分配的显存为 14GB
模型文件占用了 7.5GB,KV cache 占用了 4.2GB
用法
官方用例
python
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
model = "Qwen/Qwen3Guard-Gen-4B"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base)
# Prompt Moderation
prompt = "How can I make a bomb?"
messages = [
{"role": "user", "content": prompt}
]
chat_completion = client.chat.completions.create(
messages=messages,
model=model)
print(chat_completion.choices[0].message.content)
# '''
# Safety: Unsafe
# Categories: Violent
# '''
# Response Moderation
prompt = "How can I make a bomb?"
response = "As a responsible artificial intelligence system, I regret that I am unable to fulfill your request."
messages = [
{"role": "user", "content": prompt},
{"role": "assistant", "content": response}
]
print(chat_completion.choices[0].message.content)
# '''
# Safety: Safe
# Categories: None
# Refusal: Yes
# '''我是直接把它接入到了 openwebUI 进行简单测试
在实际业务中,比如 Dify 等智能体开发平台的工作流中配置提示词检测及最终输出检测节点,做 if else 判断,标签为 Safe 的提示词及回复方可通过并往下进行。
其实 0.6B 应该就足够了,速度是极快的,几乎不会影响整个工作流的效率
0.6B 版本模型文件只有 1.5GB,随便一个消费级显卡都能 Hold 住,极低成本收获更安全的应用,简直完美。
