
Appearance
大家好,我是Ai学习的老章
大家好,我是 Ai 学习的老章
之前介绍并测试过 DeeoSeep 最新开源 OCR 模型的 Latex 公式识别能力:DeepSeek 最新开源 OCR 模型,实测,不如百度,然后介绍了一个基于 Web 界面(React 前端+FastAPI 后端)的 OCR 工具:一个强大的开源 OCR 工具,DeepSeek OCR 驱动还有支持Windows的DeepSeek-OCR桌面客户端
https://docs.vllm.ai/projects/recipes/en/latest/DeepSeek/DeepSeek-OCR.html#configuration-tips
DeepSeek-OCR:光学 2D 上下文压缩的原型。该模型使用 SAM 基编码器和 16 倍卷积压缩器以及 CLIP-large 骨干,旨在降低激活成本并减少视觉标记。其解码器是 DeepSeek-3B-MoE,激活了 64 个路由专家中的 6 个(加上 2 个共享),大约有 5.7 亿个活跃参数。单个模型支持多种分辨率。
文档首先转化为视觉标记,然后紧凑的解码器重建文本。你可以获得 7 到 20 倍的标记减少,同时控制保真度,这是“光学记忆”和 LLMs 中长上下文压缩的途径。
分辨率模式
- 小型:512²分辨率,64个标记
- 小型:640²分辨率,100个标记
- 基础:1024²分辨率,256个标记
- 大型:1280²分辨率,400个标记
- 高达模式:结合多个 640²局部视图与一个 1024²全局视图,生成大约 n×100 + 256 个标记(n 的范围从 2 到 9)
- Gundam-M 模式:使用 1024²个局部视图配对一个 1280²个全局视图(产生大约 n×256 + 400 个令牌)
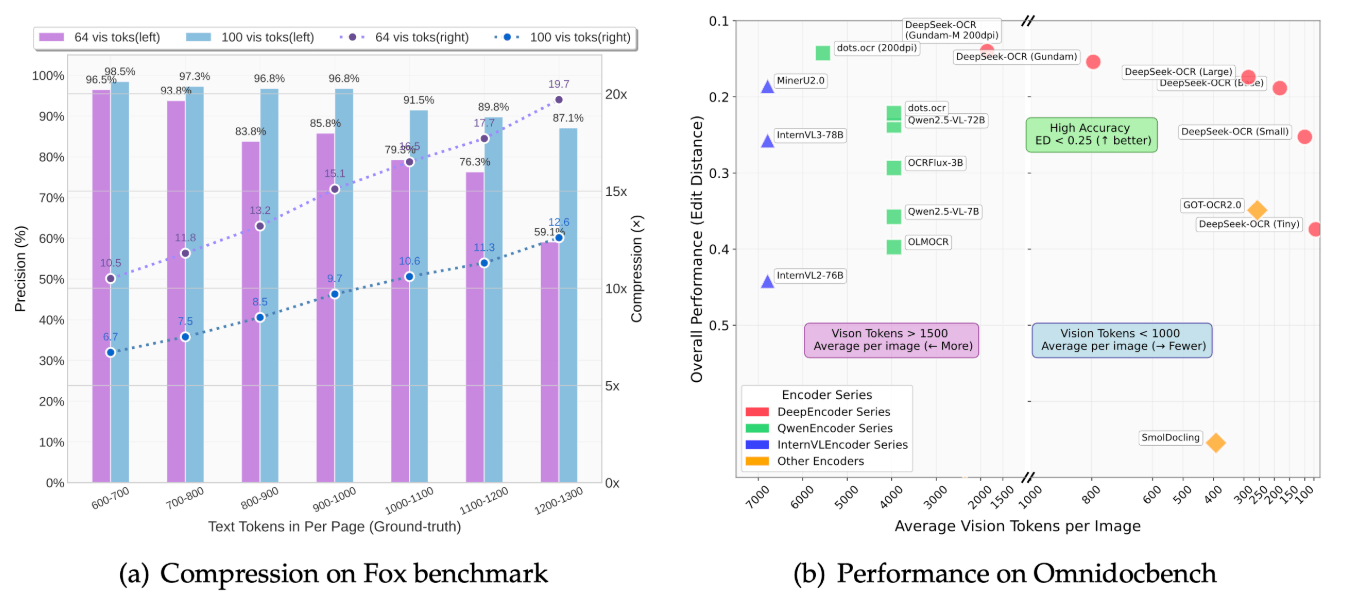
压缩研究(Fox 基准)
- 当文本令牌的数量在视觉令牌数量的十倍以内时,解码准确率约为97%(大约9–10倍压缩)
- 即使在20倍压缩比的情况下,也能保持约60%的准确率
- 使用64个视觉标记,准确率在10.5×压缩时为96.5%,在19.7×压缩时为59.1%
- 使用100个视觉标记,准确率在6.7×压缩时为98.5%,在12.6×压缩时为87.1%
OmniDocBench 结果
- 使用 100 个视觉标记,模型达到 0.221 编辑距离(英文总体),超过使用 256 个标记的 GOT-OCR 2.0,后者得分为 0.287
- 400个标记(约285个有效标记),其性能达到0.138,与最先进的系统相当
- 在高达模式下(少于 800 个标记;n×100 + 256),其性能优于 MinerU 2.0(约 6.8k 个标记),在 200 dpi 时达到 0.127–0.123
- 演示文稿通常需要约 64 个标记,书籍和报告大约需要 100 个,而报纸需要高达模式或高达-M 模式
与 GOT / OCR-2.0 相比: DeepSeek-OCR 是以压缩为主导的,量化了文本到视觉标记的比例(约 97% 在约 10 倍压缩下;<800 个标记的高达尼姆),并探索“光学记忆”以提高长上下文效率。GOT(StepFun)是统一的 OCR-2.0 工作马车,涵盖了文本、表格、图表、化学公式和几何图形。它们共享相同的端到端编码器-解码器原则,但重点不同:DeepSeek = 光学上下文压缩,GOT = 广泛的任务覆盖。
吞吐量与部署
- 每天约 20 万页在一块 A100-40G 上
- 在一个 20 节点集群上扩展到每天约 330 万页(每个节点 8 块 A100-40G)
- DeepSeek-OCR 可以处理大约约 100 种语言(训练覆盖率因书写系统而异),并且还可以“深度解析”文档中的图像,例如将图表转换为 HTML 表格,化学公式转换为 SMILES 字符串,以及几何图形转换为结构化的坐标数据
图表说明:DeepSeek-OCR 将图表转换为 HTML 表格以实现端到端的 OCR。OneChart 专注于图表结构,通过添加辅助标记和置信评分来提高数字准确性并在图表基准测试中提升 AP 值
公式:UniMER/UniMERNet 为类似 MinerU 的模块化管道提供专用的图像到 LaTeX 识别。DeepSeek-OCR 相反地在单一压缩的端到端解码中恢复公式。
训练设置
两阶段训练:先训练 DeepEncoder,再训练完整模型,使用 4 路管道并行和 12 层 MoE 解码器
数据混合:70% OCR,20% 视觉,10% 文本(序列长度 8192)
运行在 Torch 2.6 / CUDA 11.8 / Py 3.12,Flash-Attn 2 可选,vLLM 路径用于 PDFs/批处理
规模。编码器≈380M,解码器 3B MoE(约 570M 激活)
https://docs.unsloth.ai/new/deepseek-ocr-run-and-fine-tune#fine-tuning-deepseek-ocr
https://mp.weixin.qq.com/s/BSWVefwplAY0VFGrQ1rZVQ

速度
让它“起飞”的配置
那次疯狂测试所用的硬件如下:
- **GPU:**1 × NVIDIA RTX A6000 ADA
- **CPU:**Ryzen 1700
- **内存:**32 GB
- 环境: 在 WSL 中运行 Docker + FastAPI
然而,平均每页耗时_不到一秒_ 。这是另一种层次的效率。
官方教程
uv venv
source .venv/bin/activate
# Until v0.11.1 release, you need to install vLLM from nightly build
uv pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly --extra-index-url https://download.pytorch.org/whl/cu129 --index-strategy unsafe-best-matchvllm serve deepseek-ai/DeepSeek-OCR --logits_processors vllm.model_executor.models.deepseek_ocr:NGramPerReqLogitsProcessor --no-enable-prefix-caching --mm-processor-cache-gb 0DeepSeek-OCR@Ollama
ollama v0.13 现已支持 DeepSeek-OCR!
ollama run deepseek-ocr
使用 ollama 的命令行界面尝试一下,或者直接通过 ollama 的 API 使用该模型!
