
Appearance
大家好,我是 Ai 学习的老章
前文我在【教程】DeepSeek-OCR 本地部署(上):CUDA 升级 12.9,vLLM 升级至最新稳定版一文中提到,vLLM 0.11.2 稳定版原生支持 DeepSeek-OCR,且兼容 OpenAI API 格式在线推理,操作更便捷。但 vLLM 0.11.1 及以上版本默认要求 CUDA 12.9,需先完成 CUDA 升级。完成升级后,我用最新版 vLLM 本地成功部署了 DeepSeek-OCR,用 Python 写了一个 api_server.py,使其更便捷滴支持本地图片和 PDF 文档
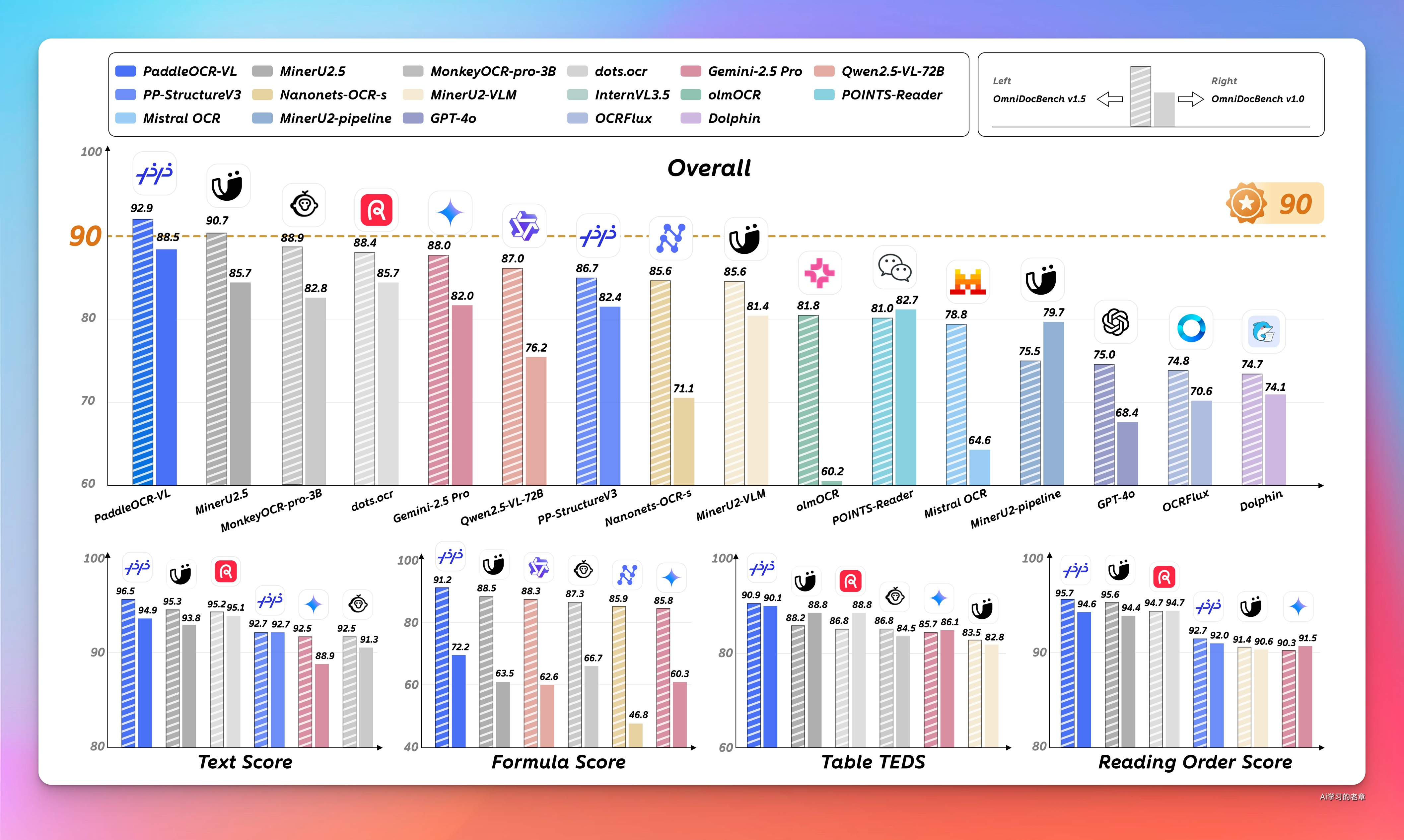
不过说实话,我测试了 N 多题目,DeepSeek-OCR 效果不如更小参数的 PaddleOCR-VL,本文我试了最新版vLLM本地部署显存占用更小的PaddleOCR,验证了api_server.py在简单修改模型名称后依然好用。
1、PaddleOCR 简介
PaddleOCR-VL 是一款面向文档解析的 SOTA 且资源高效的模型。其核心组件为 PaddleOCR-VL-0.9B——一个非常轻量级的视觉语言模型 (VLM),通过将 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型融合,实现精准的元素识别。
2、PaddleOCR 本地部署
1️⃣ 下载模型文件
bash
pip install modelscope
modelscope download --model PaddlePaddle/PaddleOCR-VL --local_dir ./PaddleOCR2️⃣ vLLM Docker 部署 PaddleOCR
bash
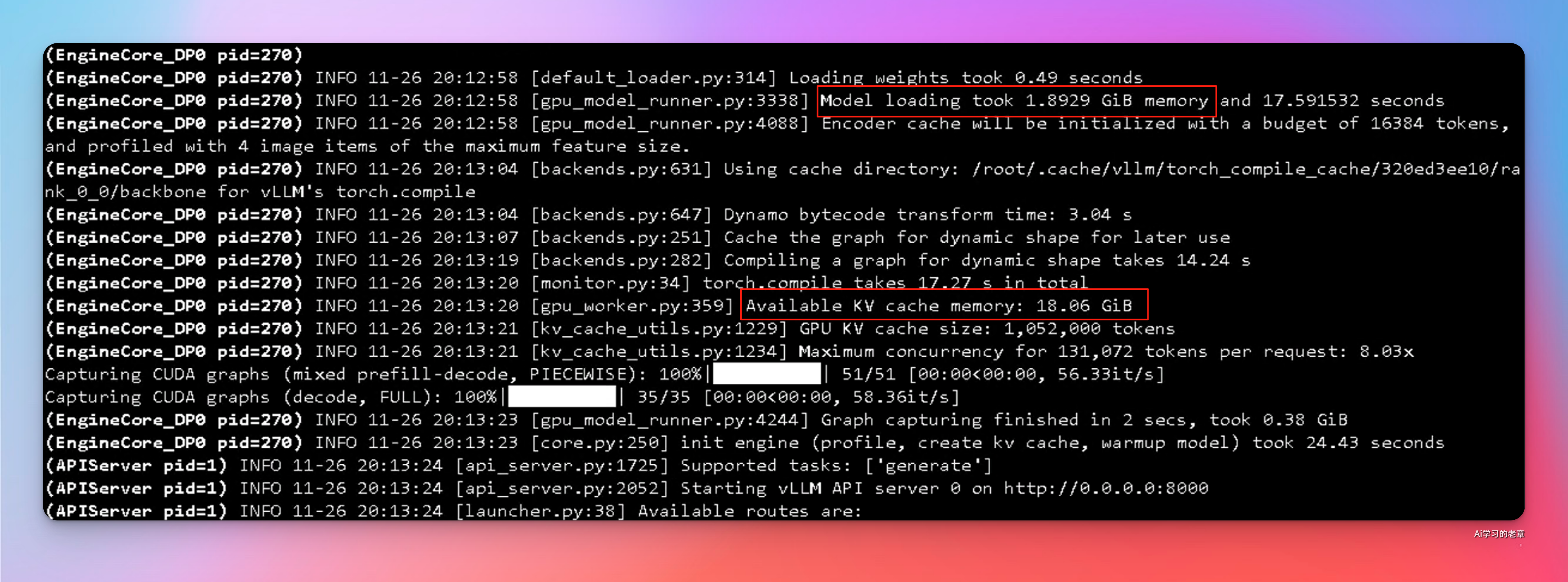
docker run -d --rm --runtime=nvidia --name paddle-ocr --ipc=host --gpus '"device=1"' -p 8000:8000 -v /data/llm-models:/models vllm/vllm-openai:v0.11.2 --model /models/PaddleOCR --max-num-batched-tokens 16384 --port 8000 --no-enable-prefix-caching --mm-processor-cache-gb 0 --trust_remote_code
#https://docs.vllm.ai/projects/recipes/en/latest/PaddlePaddle/PaddleOCR-VL.html我用单卡 4090 跑,显存的占用只有 1.89GB,剩余空间留给了 KV cache
3、API 修改,运行
前文中的 api_server.py 仅需把 DeepSeekOCR 修改为 PaddleOCR 即可
在一个新的终端 中,运行以下命令:
bash
uvicorn api_server:app --host 0.0.0.0 --port 8002
调用方法重复一下
- URL:
/models/v1/models/deepseek-ocr/inference - 方法 (Method):
POST - 内容类型 (Content-Type):
multipart/form-data
表单数据参数:
| 参数 | 类型 | 是否必须 | 描述 | 默认值 |
|---|---|---|---|---|
file | 文件 (File) | 是 | 需要处理的 PDF (.pdf) 或图像 (.png, .jpg, .jpeg) 文件。 | - |
prompt | 字符串 (String) | 否 | 一个可选的文本提示,用于指导 OCR 模型的输出格式或焦点。 | "Convert the document to markdown." |
bash
## 示例 1: 处理 PDF 文件
curl -X POST "http://localhost:8002/models/v1/models/PaddleOCR/inference" \
-F "file=@/path/to/your/report.pdf"
# 示例 2: 处理图像文件
curl -X POST "http://localhost:8002/models/v1/models/PaddleOCR/inference" \
-F "file=@/path/to/your/receipt.png"
# 示例 3: 使用自定义提示处理文件
curl -X POST "http://localhost:8002/models/v1/models/PaddleOCR/inference" \
-F "file=@/path/to/your/document.pdf" \
-F "prompt=将此文档中的所有表格提取为 markdown 格式。"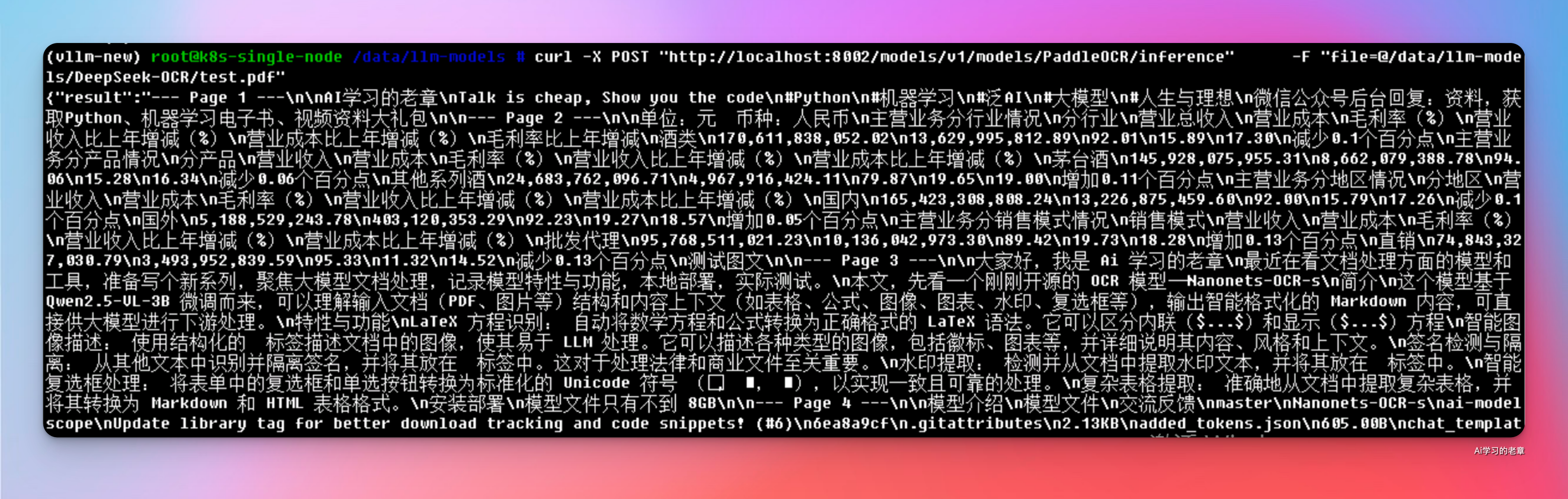
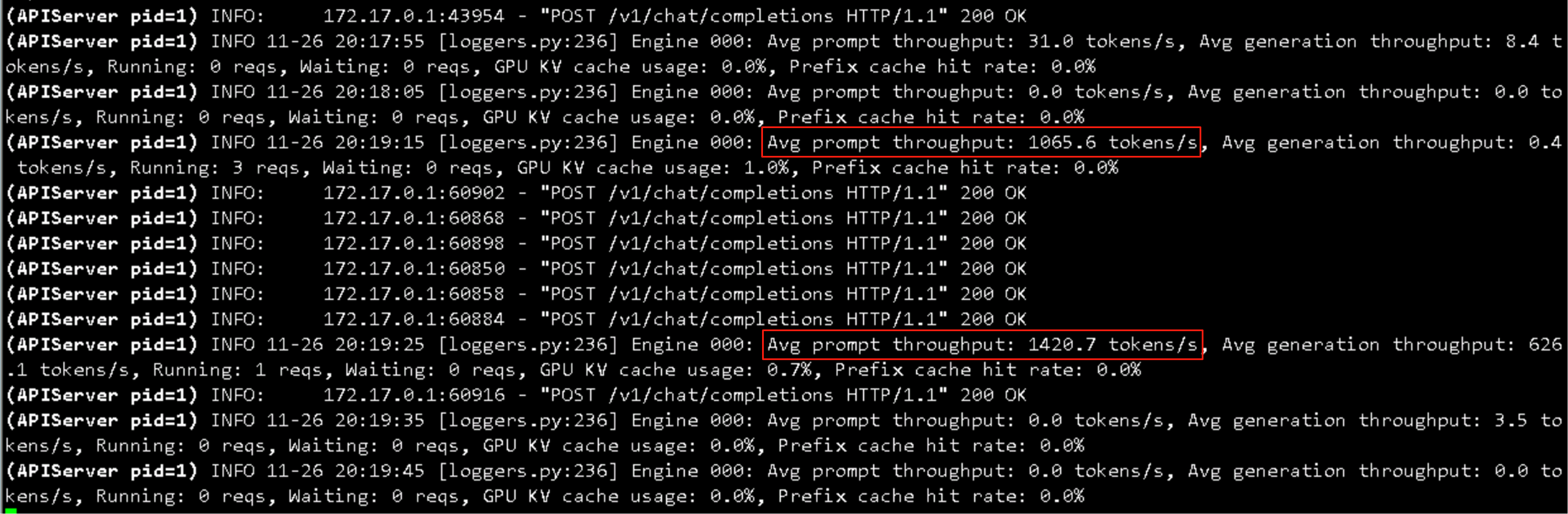
速度也是超级快
一个强大的开源 OCR 工具,基于 DeepSeek OCR, DeepSeek-OCR 桌面客户端,Windows 用户优先体验
